本文共 21346 字,大约阅读时间需要 71 分钟。
这两天把DataLoader的源代码的主要内容进行了一些分析,基于版本0.4.1。当然,因为内容比较多,没有全部展开,这里的主要内容是DataLoader关于数据加载以及分析PyTorch是如何通过Python本身的multiprocessing和Threading等库来保证batch是顺序取出的。额外的内容都会给出链接,在这里不会详细展开。
一点推荐
作为CSDN的忠实用户,最近发现CSDN学院上了一些对新手比较友好的课程。以我的切身体会来看,对于想要了解机器学习算法或者python编程语言的同学,非常有帮助。还记得我最开始学习python的时候,看的是一本写给小孩子的书《趣学Python——教孩子学编程》。
虽然这本书不错,但是确实有些过于简单了,而CSDN提供的课程有两门对现在的我来讲还是有相当大的帮助,老师讲课水平高,配合丰富的例子,容易让人掌握知识点,下面推荐两门课程:
人工智能在网络领域的应用与实践:
ps: 如果想要系统学习python的朋友,下面这门课是涵盖了python基础语法、web开发、数据挖掘以及机器学习,是CSDN强力推荐的课程,有需要的朋友可以看看哈:
Python全栈工程师:
0.前言(楔子)
本篇关于DataLoader源码的分析是继之后的第2篇源码分析,相比前一篇的内容。本篇内容完全基于Python语言范畴内,因为会比较直接一些,容易阅读。
输入数据PipeLine
pytorch 的数据加载到模型的操作顺序是这样的:① 创建一个 Dataset 对象
DataLoader 对象 ③ 循环这个 DataLoader 对象,将img, label加载到模型中进行训练 dataset = MyDataset()dataloader = DataLoader(dataset)num_epoches = 100for epoch in range(num_epoches): for img, label in dataloader: ....
所以,作为直接对数据进入模型中的关键一步, DataLoader非常重要。
首先简单介绍一下DataLoader,它是PyTorch中数据读取的一个重要接口,该接口定义在中,只要是用PyTorch来训练模型基本都会用到该接口(除非用户重写…),该接口的目的:将自定义的Dataset根据batch size大小、是否shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练。
官方对DataLoader的说明是:
“数据加载由数据集和采样器组成,基于python的单、多进程的iterators来处理数据。”
关于iterator和iterable的区别和概念请自行查阅,在实现中的差别就是iterators有
__iter__和__next__方法,而iterable只有__iter__方法。
1.DataLoader
先介绍一下DataLoader(object)的参数:
-
dataset(Dataset): 传入的数据集
-
batch_size(int, optional): 每个batch有多少个样本
-
shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序
-
sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
-
batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
-
num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
-
collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数
-
pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
-
drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了…
如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。 -
timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
-
worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on each
worker subprocess with the worker id (an int in[0, num_workers - 1]) as input, after seeding and before data loading. (default: None)
显然,根据上面参数的解释,DataLoader这个类就是进行数据的初始化的操作,
class DataLoader(object): __initialized = False def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None): self.dataset = dataset self.batch_size = batch_size self.num_workers = num_workers ... if sampler is not None and shuffle: raise ValueError('sampler option is mutually exclusive with "shuffle"') ... if batch_sampler is None: if sampler is None: if shuffle: sampler = RandomSampler(dataset) else: sampler = SequentialSampler(dataset) batch_sampler = BatchSampler(sampler, batch_size, drop_last) self.sampler = sampler self.batch_sampler = batch_sampler self.__initialized = True ... def __iter__(self): return _DataLoaderIter(self) ... 这里我们主要看__init__()和__iter__():
① 数据的shuffle和batch处理
- RandomSampler(dataset)
- SequentialSampler(dataset)
- BatchSampler(sampler, batch_size, drop_last)
② 因为DataLoader只有__iter__()而没有实现__next__()
所以DataLoader是一个iterable而不是iterator。
这个iterator的实现在_DataLoaderIter中 1.1 DataLoader之RandomSampler(dataset)、 SequentialSampler(dataset)
这两个类的实现是在dataloader.py的同级目录下的
中实现了一个父类Sampler,以及SequentialSampler,RandomSampler和BatchSampler等五个继承Sampler的子类
这里面的Sampler的实现是用C/C++实现的,这里的细节暂且不表。
我们这里需要知道的是:对每个采样器,都需要提供__iter__方法,这个方法用以表示数据遍历的方式和__len__方法,用以返回数据的长度
class Sampler(object): r"""Base class for all Samplers. Every Sampler subclass has to provide an __iter__ method, providing a way to iterate over indices of dataset elements, and a __len__ method that returns the length of the returned iterators. """ def __init__(self, data_source): pass def __iter__(self): raise NotImplementedError def __len__(self):raise NotImplementedErrorclass SequentialSampler(Sampler): r"""Samples elements sequentially, always in the same order. Arguments: data_source (Dataset): dataset to sample from """ def __init__(self, data_source): self.data_source = data_source def __iter__(self): return iter(range(len(self.data_source))) def __len__(self): return len(self.data_source)class RandomSampler(Sampler): r"""Samples elements randomly, without replacement. Arguments: data_source (Dataset): dataset to sample from """ def __init__(self, data_source): self.data_source = data_source def __iter__(self): return iter(torch.randperm(len(self.data_source)).tolist()) def __len__(self):return len(self.data_source)if __name__ == "__main__": print(list(RandomSampler(range(10)))) #[2, 8, 3, 5, 9, 4, 6, 0, 1, 7] print(list(SequentialSampler(range(10)))) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
可以看出RandomSampler等方法返回的就是DataSet中的索引位置(indices),其中,在子类中的__iter__方法中,需要返回的是iter(xxx)(即iterator)的形式:
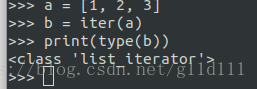
#### 以下两个代码是等价的for data in dataloader: ...#### 等价与iters = iter(dataloader)while 1: try: next(iters) except StopIteration: break
此外,torch.randperm()的用法如下:
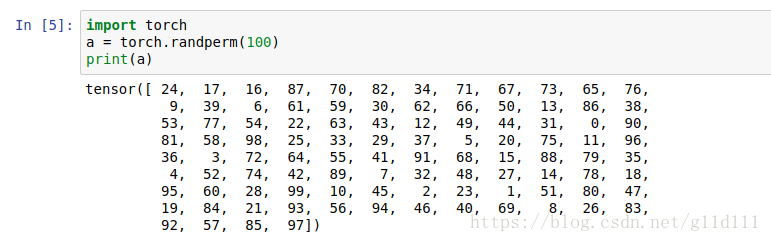
1.2 DataLoader之BatchSampler(Sampler)
BatchSampler是wrap一个sampler,并生成mini-batch的索引(indices)的方式
这里主要看__iter__方法,可以看到,代码的思路很清楚明白的展示了batch indices的是如何取出的。
class BatchSampler(Sampler): r"""Wraps another sampler to yield a mini-batch of indices. Args: sampler (Sampler): Base sampler. batch_size (int): Size of mini-batch. drop_last (bool): If ``True``, the sampler will drop the last batch if its size would be less than ``batch_size`` Example: >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False)) [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]] >>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True)) [[0, 1, 2], [3, 4, 5], [6, 7, 8]] """ def __init__(self, sampler, batch_size, drop_last): if not isinstance(sampler, Sampler): raise ValueError("sampler should be an instance of " "torch.utils.data.Sampler, but got sampler={}" .format(sampler)) if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or \ batch_size <= 0: raise ValueError("batch_size should be a positive integeral value, " "but got batch_size={}".format(batch_size)) if not isinstance(drop_last, bool): raise ValueError("drop_last should be a boolean value, but got " "drop_last={}".format(drop_last)) self.sampler = sampler self.batch_size = batch_size self.drop_last = drop_last def __iter__(self): batch = [] # 一旦达到batch_size的长度,说明batch被填满,就可以yield出去了 for idx in self.sampler: batch.append(idx) if len(batch) == self.batch_size: yield batch batch = [] if len(batch) > 0 and not self.drop_last: yield batch def __len__(self): # 比如epoch有100个样本,batch_size选择为64,那么drop_last的结果为1,不drop_last的结果为2 if self.drop_last: return len(self.sampler) // self.batch_size else: return (len(self.sampler) + self.batch_size - 1) // self.batch_sizeif __name__ == "__main__": print(list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))) # [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]] print(list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))) # [[0, 1, 2], [3, 4, 5], [6, 7, 8]] 2._DataLoaderIter
这个_DataLoaderIter其实就是DataLoader类的__iter__()方法的返回值:
注意,这个_DataLoaderIter中*init(self, loader)*中的loader就是对应的DataLoader类的实例。
class _DataLoaderIter(object): r"""Iterates once over the DataLoader's dataset, as specified by the sampler""" def __init__(self, loader): self.dataset = loader.dataset # 将一个list的sample组成一个mini-batch的函数 ... # 监听事件完成与否——https://www.cnblogs.com/lcchuguo/p/4687348.html self.done_event = threading.Event() # self.sample_iter是iterator:迭代器 self.sample_iter = iter(self.batch_sampler) # 随机种子,用于worker_init_fn的初始化 base_seed = torch.LongTensor(1).random_().item() if self.num_workers > 0: # worker_init_fn是worker初始化函数 self.worker_init_fn = loader.worker_init_fn # index_queue 索引队列 每个worker进程对应一个: self.index_queues = [multiprocessing.Queue() for _ in range(self.num_workers)] # worker 队列索引 self.worker_queue_idx = 0 # worker_result_queue 进程间通信 # multiprocessing.SimpleQueue是multiprocessing.Queue([maxsize])的简化,只有三个方法------empty(), get(), put() self.worker_result_queue = multiprocessing.SimpleQueue() # batches_outstanding # 当前已经准备好的 batch 的数量(可能有些正在准备中) # 当为 0 时, 说明, dataset 中已经没有剩余数据了。 # 初始值为 0, 在 self._put_indices() 中 +1,在 self.__next__ 中-1 self.batches_outstanding = 0 self.worker_pids_set = False # shutdown为True是关闭worker self.shutdown = False # send_idx, rcvd_idx——发送索引,接收索引 # send_idx 用来记录 这次要放 index_queue 中 batch 的 idx self.send_idx = 0 # rcvd_idx 用来记录 这次要从 data_queue 中取出 的 batch 的 idx self.rcvd_idx = 0 # 因为多进程,可能会导致 data_queue 中的batch乱序 # 用这个来保证 batch 的返回是按照send_idx升序出去的。 self.reorder_dict = { } # 创建num_workers个worker进程来处理 self.workers = [ multiprocessing.Process( target=_worker_loop, args=(self.dataset, self.index_queues[i], self.worker_result_queue, self.collate_fn, base_seed + i, self.worker_init_fn, i)) for i in range(self.num_workers)] # 这里暂不分析CUDA或者timeout的情况 if self.pin_memory or self.timeout > 0: ... else: # data_queue就是self.worker_result_queue(MultiProcessing.SimpleQueue()类型) # 这个唯一的队列 self.data_queue = self.worker_result_queue # 设置守护进程 for w in self.workers: w.daemon = True # ensure that the worker exits on process exit w.start() ... # prime the prefetch loop # 初始化的时候,就将 2*num_workers 个 (batch_idx, sampler_indices) 放到 index_queue 中 for _ in range(2 * self.num_workers): self._put_indices() 在_DataLoaderIter中,首先来看self.workers,这个成员变量对应是开个num_workers个进程来处理数据,对应的函数是_worker_loop
2.1 _worker_loop
这部分多进程执行的代码的目的:从index_queue中取索引,然后通过collate_fn处理数据,然后再将处理好的 batch 数据放到 data_queue 中。(发送到队列中的idx是self.send_idx)
传入的参数:
args=(self.dataset, self.index_queues[i],self.worker_result_queue, self.collate_fn, base_seed + i, self.worker_init_fn, i)
- 1.dataset
- 2.index_queue中的其中之一(
multiprocessing.Queue()) - 3.进程共享的data_queue(
multiprocessing.SimpleQueue()) - 4.collate_fn
- (是pid?)
- 6.worker初始化函数
- 7.第i个worker
显然,可以看出,对应**_worker_loop**,数据队列是共享的SimpleQueue(),而索引队列是每个worker独有的Queue()。
def _worker_loop(dataset, index_queue, data_queue, collate_fn, seed, init_fn, worker_id): global _use_shared_memory _use_shared_memory = True ... torch.set_num_threads(1) random.seed(seed) # 保证每个worker的随机种子相同 torch.manual_seed(seed) # 初始化worker if init_fn is not None: init_fn(worker_id) # 以Linux为例, #class ManagerWatchdog(object): # def __init__(self): # self.manager_pid = os.getppid() # # def is_alive(self): # os.getppid--->获得父进程的id # return os.getppid() == self.manager_pid watchdog = ManagerWatchdog() # 处理代码 while True: try: # MANAGER_STATUS_CHECK_INTERVAL = 5.0 # r = 从索引队列里取索引 r = index_queue.get(timeout=MANAGER_STATUS_CHECK_INTERVAL) except queue.Empty: if watchdog.is_alive(): continue else: break if r is None: break idx, batch_indices = r try: # 传到 collate_fn 的数据是 list of dataset[i] (i in batch_indices) samples = collate_fn([dataset[i] for i in batch_indices]) except Exception: data_queue.put((idx, ExceptionWrapper(sys.exc_info()))) else: # 将从索引队列取出的数据放进data_queue中,并将samples删除 data_queue.put((idx, samples)) del samples
2.2 self._put_indices(self)
根据2.1,我们知道了_DataLoaderIter是如何从不同的index_queue中消费数据并将数据转换为data放入同一个data_queue中。
但是在_DataLoaderIter的构造函数中,index_queue还都是空队列,没法进行"消费"。所以,在构造函数的最后,有如下代码:
# prime the prefetch loop # 初始化的时候,就将 2*num_workers 个 (batch_idx, sampler_indices) 放到 index_queue 中 for _ in range(2 * self.num_workers): self._put_indices()
它其实就是初始化,这是因为之前的num_workers个index_queue都是空的,所以务必要初始化一下!
那么这个核心的内容self._put_indices(),其代码不多,如下:
def _put_indices(self): assert self.batches_outstanding < 2 * self.num_workers indices = next(self.sample_iter, None) if indices is None: return self.index_queues[self.worker_queue_idx].put((self.send_idx, indices)) # 保证worker_queue_idx在[0, self.num_workers)之间。 self.worker_queue_idx = (self.worker_queue_idx + 1) % self.num_workers # batches_outstanding表示index_queue队列里有几个batch可供"消费" self.batches_outstanding += 1 # send_idx 发送索引,和rcvd_idx需要对应,后面会提到 self.send_idx += 1
① self.batches_outstanding的内容在构造函数中说明,初始值为0,在_put_indices()中会加1
② 从self.sample_iter这个iterator中返回一个batch对应的索引,具体内容在之前的BatchSampler(Sampler)提到
③ 向对应的self.index_queues[i]中放入(send_idx, indices)内容,其中i = worker_queue_idx通过
④ batches_outstanding+=1 表明batches加1
⑤ send_idx+= 1 记录从sample_iter中发送索引到index_queue的次数
疑问
当我看到这里的时候,有一个疑问,因为在_DataLoaderIter的构造函数中,num_workers个_worker_loop进程已经开始从不同的index_queue取数据,制作后放入data_queue了。
但是以num_workers = 2为例,如果epoch有很多样本,比如10000个,但是batch的size不大,比如为32,那么所有的2个index_queue所得到的数据只有2项,即64个索引,并没有将数据全部制作成indices放入到index_queue里啊。
答疑
需要注意,_DataLoaderIter是一个迭代器,接收的参数就是DataLoader的一个实例,而_DataLoaderIter的__next__方法用yield的方式(生成器)是很节省内存的,即数据不是一次性加载到内存中再一点点挤牙膏挤出来,而是需要的时候再取出,很安全且便捷。
所以说,对于迭代器,我们不需要一次性把数据全load进所有的index_queue中,而是根据需要load就好,这样也避免了队列过大可能带来的额外开销。
2.3 self.__next__(self)
第一部分,就是如果num_workers = 0的话,
就用一个普通的iterator加collate_fn数据处理,没什么特殊。def __next__(self): if self.num_workers == 0: # same-process loading indices = next(self.sample_iter) # may raise StopIteration batch = self.collate_fn([self.dataset[i] for i in indices]) if self.pin_memory: batch = pin_memory_batch(batch) return batch
下面才是重点内容!!
# check if the next sample has already been generated① if self.rcvd_idx in self.reorder_dict: batch = self.reorder_dict.pop(self.rcvd_idx) return self._process_next_batch(batch)② if self.batches_outstanding == 0: self._shutdown_workers() raise StopIteration③ while True: assert (not self.shutdown and self.batches_outstanding > 0) idx, batch = self._get_batch() self.batches_outstanding -= 1 if idx != self.rcvd_idx: # store out-of-order samples self.reorder_dict[idx] = batch continue return self._process_next_batch(batch) next = __next__ # Python 2 compatibility
将上面的核心代码分成①,②,③三部分,
我们分析的顺序是③ ① ② ③ While True: 因为这里我们还不知道self.rcvd_idx和self.reorder_dict的用法,所以先关注第③部分最后的while True内容: 在构造函数中,我们有: self.shutdown = False self._put_indices使得self.batches_outstanding = 2 * num_workers
下面进入函数self._get_batch(),如下所示,就是从data queue里面取数据,**idx是_put_indices()中的self.send_idx **
def _get_batch(self): if self.timeout > 0: try: return self.data_queue.get(timeout=self.timeout) except queue.Empty: raise RuntimeError('DataLoader timed out after {} seconds'.format(self.timeout)) else: return self.data_queue.get() 接着,对self.batches_outstanding减1(也就是预备好的batch个数需要减1)。
因为**idx是_put_indices()中的self.send_idx **,而self.rcvd_idx是接收到的idx,判断它们是否一致。
if idx != self.rcvd_idx: # store out-of-order samples self.reorder_dict[idx] = batch continue
需要注意,self.rcvd_idx初始值为0,它只在_process_next_batch中产生变化(+1)
def _process_next_batch(self, batch): self.rcvd_idx += 1 self._put_indices() ... return batch # 调用_process_next_batch的时候,处理了接收索引(rcvd_idx),并且通过调用`self._put_indices()`,# 向index_queue中扔数据,并使得发送索引数加1, 在data_queue中可以被处理的batch数量加1# 而实际上batch本身不变
这里说一下为什么是在data_queue中可以被处理的batch数量加1:因为有num_workers个守护子进程是对index_queue中的数据进行处理的,当index_queue中有新的内容时,若这些守护子进程有空闲,则会对其从index_queue中取出,并进行处理,将batch size个索引经过处理放入data_queue中。
需要额外注意的是:当index_queue没有内容的时候,执行self._put_indices()是不会使得self.send_idx和self.batches_outstanding的值发生变化的,这也就是我们在_DataLoaderIter的构造函数最后可以对其进行一个初始化的原因。
其实说到这里,可能还是很迷糊,下面在__next__()的一些关键位置加注了信息输出
def __next__(self): if self.num_workers == 0: # same-process loading indices = next(self.sample_iter) # may raise StopIteration batch = self.collate_fn([self.dataset[i] for i in indices]) if self.pin_memory: batch = pin_memory_batch(batch) return batch # check if the next sample has already been generated if self.rcvd_idx in self.reorder_dict: print('从不定序dict中获取对应的batch:', self.rcvd_idx) batch = self.reorder_dict.pop(self.rcvd_idx) return self._process_next_batch(batch) if self.batches_outstanding == 0: self._shutdown_workers() raise StopIteration while True: assert (not self.shutdown and self.batches_outstanding > 0) idx, batch = self._get_batch() # initial batches_outstanding = 4 self.batches_outstanding -= 1 print("batches outstanding:", self.batches_outstanding) if idx != self.rcvd_idx: # store out-of-order samples print("send_idx != rcvd_idx:", idx, self.rcvd_idx) self.reorder_dict[idx] = batch continue print("send_idx = rcvd_idx:", idx) print('-' * 20) return self._process_next_batch(batch) 自定义了一个DataLoader,并对其进行遍历,结果如下:
#### 第1个next# 经过self._get_batch()之后,可以处理的batch数据-1,从4变为3batches outstanding: 3# 发送的idx(send_idx) = 1, 而第一次next的时候rcvd_idx = 0,此时用self.reorder_dict这个字典# 把idx = 1对于的batch记录下来send_idx != rcvd_idx: 1 0# 这里self.reorder_dict = {1: correspond_batch}, 因为不满足idx == self.rcvd_idx, # 所以继续执行循环语句。# 经过self._get_batch()之后,可以处理的batch数据-1,从3变为2batches outstanding: 2# 这下子idx和rcvd_idx相等了!执行self._process_next_batch(batch)send_idx = rcvd_idx: 0#执行self._process_next_batch(batch),使rcvd_idx += 1, _put_indices()# --->也就是send_idx += 1和batches_outstanding += 1(如果self.sample_iter不为空)--------------------#### 第2个next# 对于`__next__()`中的代码段①从不定序dict中获取对应的batch: 1**执行self._process_next_batch(batch),使rcvd_idx += 1, _put_indices()--->也就是send_idx += 1和outstanding += 1**#### 第3个nextbatches outstanding: 3send_idx != rcvd_idx: 3 2batches outstanding: 2send_idx = rcvd_idx: 2--------------------从不定序dict中获取对应的batch: 3batches outstanding: 3send_idx != rcvd_idx: 5 4batches outstanding: 2send_idx = rcvd_idx: 4 ① 检查样本是否已经生成:
由上面的例子可以看出,因为rvcd_idx = 1对于的send_idx = 1样本已经存在且放置于self.reorder_dict中,
self.reorder_dict的目的是保证batch size数目的样本在每次next输出的时候是根据rcvd_idx进行升序输出的。 # check if the next sample has already been generated if self.rcvd_idx in self.reorder_dict: print('从不定序dict中获取对应的batch:', self.rcvd_idx) batch = self.reorder_dict.pop(self.rcvd_idx) return self._process_next_batch(batch) ② 检查是否还有剩余样本:
如果batch都被处理完了,那么就关闭所有的处理_worker_loop进程。 if self.batches_outstanding == 0: self._shutdown_workers() raise StopIteration
2.4 default_collate(batch)
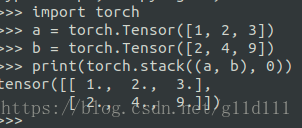
default_collate是DataLoader的默认collate_fn,并传给了_DataLoaderIter作为_worker_loop处理数据的基本函数,这里我们只需要看torch.stack就好了,它的目的:将batch size个样本合成为一个batch(加了一个维度)
def default_collate(batch): r"""Puts each data field into a tensor with outer dimension batch size""" error_msg = "batch must contain tensors, numbers, dicts or lists; found {}" # elem_type = type(batch[0]) # if isinstance(batch[0], torch.Tensor): # print(isinstance(batch[0], torch.Tensor)) if elem_type == torch.Tensor: out = None if _use_shared_memory: ... return torch.stack(batch, 0, out=out) ... 我们暂时需要关注一个的用法即可:
3. 总结
① DataLoader本质上就是一个iterable(跟python的内置类型list等一样),并利用多进程来加速batch data的处理,使用yield来使用有限的内存
② Queue的特点当队列里面没有数据时: queue.get() 会阻塞, 阻塞的时候,其它进程/线程如果有queue.put() 操作,本线程/进程会被通知,然后就可以 get 成功。
当数据满了: queue.put() 会阻塞③ DataLoader是一个高效,简洁,直观的网络输入数据结构,便于使用和扩展